Как мы создали, обучили, протестировали и выпустили в свет сервис «Классификация» продукта ОКО-Скан,
использующий
технологию машинного обучения для распознавания и классификации документов? С вами команда Лигрес, и в этой
статье
мы расскажем вам об опыте разработки этого решения для автоматизации труда юристов и взыскателей.
Нами было решено создать такой сервис из-за того, что сейчас практически все компании из сферы взыскания
подготавливают документы перед подачей в суд вручную. Мы создали свое решение, и сейчас поделимся некоторыми
техническими подробностями.
AI-технологии обработки кредитного досье
Сервис «Классификация» реализован с помощью технологии OCR (машинного распознавания текста). Кроме OCR, мы
использовали технологии машинного обучения.
Принцип распознавания и классификации выглядит следующим образом:
- OCR – первое звено цикла, машинное распознавание текста. OCR обучалась на разных примерах документов,
составленных по разным шаблонам. При обучении учитывались и шрифты, и их размеры. А также – поворот
документа.
- NLP (Natural Language Processing) – второе. Анализирует текст и говорит к какому типу документа
относится
изображение. Обработка естественного языка нужна для извлечения смысла из тех слов и букв, которые
распознали
алгоритмы OCR.
- CNN (Convolutional Neural Network) – третье, и последнее. Проверяет, является ли изображение паспортом в
случаях, если NLP не знает, что это за документ. Сверточная нейронная сеть нужна, когда два прошлых
метода
распознавания текста не эффективны. Например, если текст плохо пропечатан. Такое часто происходит со
сканами
паспортов.
Каких-то особенных сложностей с внедрением OCR и распознаванием юридических документов у нас не возникало,
поскольку
они – это тот же текст, только оформленный по определенным правилам. Программа умеет с практически полной
точностью
распознавать их, потому что мы ее долго обучали именно на тех документах, которые нужны взыскателям.
Но NLP появилась не сразу, до этого использовался другой алгоритм. Почему мы его поменяли, и сделали такой
цикл
распознавания данных, который по итогу получился?
Путь к NLP и что было до
Как мы в самом начале определяли тип документа при классификации? Первоначальный алгоритм работал по
ключевому слову.
Он подразумевал за собой нахождение в документе слов, помогающих идентифицировать тип документа. Например,
нам нужно
понять, является ли документ Согласием на обработку персональных данных. Если программа найдет в тексте
слова
"Согласие на обработку персональных данных" - то да.
Это работало так:
- Файл конвертировали в изображение
- Из изображения извлекали текст
- В тексте искали одно "ключевое слово"
Но нам удалось столкнуться с такими трудностями:
- Проблема возникнет, если файл состоит более, чем из одной страницы, а ключевое слово находится только на
первой.
PDF-файлы с кредитными досье бывают длинными и состоящими из всех документов одновременно, и тогда
программа
определит тип неправильно.
- Если в документе встречается много одинаковых ключевых слов на разных страницах, и при этом - это разные
документы, то программа тоже спотыкается.
- Неточное извлечение OCR - это тоже большая проблема.
Чтобы избежать их, нужно выделить "ключевые слова" для каждой страницы документа и сделать так, чтобы python
мог
отличить один класс от другого, даже если у них есть пересечениях в ключевых словах.
Плюсуем к этому неточность OCR, которая может ошибиться: пропустить букву, поменять "О" на "0", или что-то не
увидеть… И "ключевые слова" уже не сработают.
Да, эти проблемы можно решить извлечением текста из самого PDF-файла и создать регулярное выражение для
каждого
“ключевого слова”, но это очень долго, и от неточности OCR не спасает. Да и извлечь текст из всего PDF файла
не
всегда возможно, поскольку там могут встречаться фотографии и данные в других форматах.
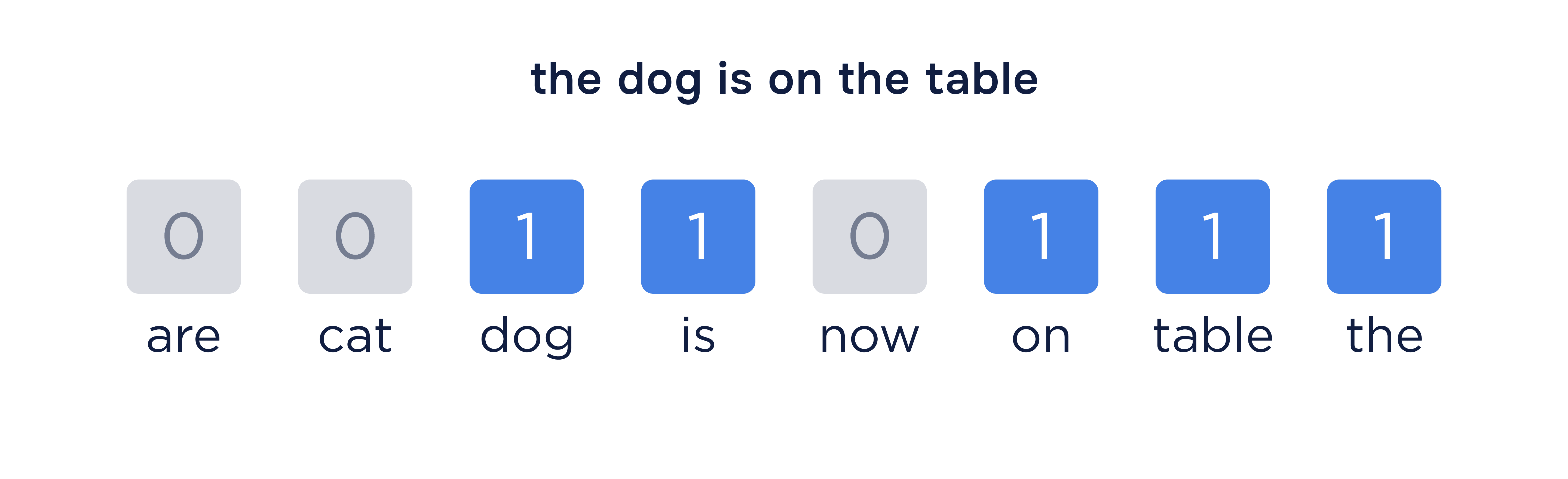
И по итогу мы внедрили в работу продукта NLP. Что поменялось?
NLP (Natural Language Processing) - это более развитый вариант поиска по "ключевым словам". Модель
преобразует текст
документа в числовой формат, где каждое число указывает на важность определенного слова или фразы. Как это
работает?
Примерно как на картинке.
Модель обучается на этих числовых значениях, изучая, какие слова и фразы чаще встречаются в документах
каждого типа.
Таким образом и идет обучение для определения конкретных типов документов.
Когда модели приходит документ на классификацию, она его текст преобразует в числа и предсказывает
вероятность того,
к какому типу относится именно этот, основываясь на обученных весах.
То есть с помощью NLP мы оцениваем сразу все слова в документе, а не ищем конкретные как в поиске по
"ключевым
словам".
Остальные проблемы, с которыми пришлось столкнуться: как связать технологии воедино, и извлекать данные из
паспортов?
Помимо этого, основных сложностей в процессе разработки продукта было две – это выбор правильных технологий и
связывание их воедино, чтобы получалась синергия, а также распознавание текста в паспортах.
Первую проблему мы решили посредством различных тестирований, и на выходе мы получили достаточно сложный
продукт с
множественной каскадной архитектурой. Какие-то блоки вышли монолитными, где-то использовались
микросервисы.
Почему так вышло? Внутри продукта ОКО-Скан существует два сервиса – «Классификация» и «Извлечение». Хоть
сейчас мы и
говорим только о первом, второй можно использовать вместе с ним, если это нужно для выполнения конкретных
задач.
Сервис «Извлечение» может, непосредственно, извлекать нужные поля из юридических документов, чтобы
сотрудники
компаний могли не переписывать их вручную. И чтобы связать два сервиса между собой мы прибегали к
длительными
тестированиям.
На этапе распознавания текстов из паспортов иногда возникали проблемы, поскольку там не такая ровная печать,
как в
других документах. Для распознавания плохо пропечатанного текста мы стали использовать CNN (свёрточную
нейронную
сеть) – она распознает конкретные пиксели и отсутствие или наличие на них определенного цвета. А если у
одной
нейросети не получается распознать текст, то мы пробуем воспользоваться другой.
У CNN следующий алгоритм работы:
- Свёртка: Сеть применяет фильтры к изображению, выделяя ключевые признаки, такие как
текстовые
области, логотипы и печати.
- Подвыборка: Сеть уменьшает размер данных, сохраняя только самые важные из выделенных
признаков.
- Классификация: На основе этих признаков сеть определяет, к какому типу относится
изображение
документа.
Но какое-то время мы не могли найти параметры для CNN. Мы перебирали такие параметры, как свертка, ядро,
размер
изображения и некоторые другие. По итогу удалось достичь 96% точности изображения – до этого мы показывали
результат
в 89%.
Разработка и первые тестирования
По ходу разработки мы перепробовали 5 алгоритмов машинного обучения, прежде чем нашли подходящий. Также, мы
постоянно
меняли и настраивали его гиперпараметры, чтобы подобрать максимально универсальные настройки под разные виды
входящих документов досье с разным качеством.
Аналогичный процесс был при выборе, дообучении и использовании алгоритмов распознавания фото и изображений с
помощью
алгоритмов нейронных сетей. В конце тестов мы остановились на использовании уникального алгоритма, который с
одной
стороны давал качество в 95-99% точного распознавания документов досье, а с другой - мог обучаться на новый
тип
документов в течении 1-2 дней.
Итоговый продукт: как ОКО-Скан выглядит и работает сейчас
На выходе, после всех доработок и тестирований мы получили уникальный и точный в своей работе сервис для
классификации кредитных досье. И мы уже имеем некоторые кейсы, в которых сервис смог многократно ускорить
процесс
подачи в суд на должников. Время обработки досье снизилось от 10-20 минут до 1-2 минут, а процент ошибок в
определении видов документов уменьшился с 10-20% до 1-2%.
Недавно мы начали работу над тем, чтобы наш сервис мог выполнять задачи по классификации и подготовке
документов для
работы с электронной исполнительной надписью нотариуса. Основной процесс такой же, как и при классификации
досье для
подачи в суд, но виды документов немного отличаются.
И самое главное – недавно у нас вышло обновление этого сервиса, в котором мы сделали интеграцию по API более
удобной.
Теперь сервис принимает досье в виде архива и может работать 24/7 без участия человека, берет в
классификацию и
отдает результат в нужную систему. До этого все работало только через SFTP, где ключевую роль в скорости
обработки
играли наши сотрудники, которые выгружали исходное досье клиента и загружали классифицированное досье после
его
обработки вручную. Также стали доступны обработка нескольких досье параллельно, сбор и учет статистики.
Сейчас сервис продолжает развиваться, мы регулярно собираем обратную связь и совершенствуем его.