ОКО-Скан – это наш продукт, созданный для классификации кредитных досье и извлечения данных из судебных и
исполнительных документов. Он состоит из двух сервисов: «Классификация» и «Извлечение», реализованных на
основе
технологий машинного обучения и оптического распознавания текста.
Решение создать такой продукт мы приняли, когда увидели потребность рынка взыскания в автоматизации работы с
судебными документами. Классификацией кредитных досье должников перед подачей в суд сотрудники компаний
занимались
вручную, извлечением данных из документов из суда и ФССП для дальнейшей работы - преимущественно тоже.
Как создавался ОКО-Скан, с какими трудностями пришлось столкнуться, какими были первые тесты и что получилось
создать
по итогу? Рассказываем в этой статье.
Зачаток идеи
Чтобы помочь компаниям избавиться от долгой и сложной ручной обработки документов, нужен был такой продукт,
который
был бы полезен на досудебной и судебной стадиях взыскания, и помогал бы заносить информацию из судебных
документов в
ERP-системы и collection-системы.
Мы выявили 2 ключевые бизнес-потребности клиентов — потребность в автоматизации процессов классификации
кредитного
досье и потребность в извлечении определенных атрибутов из судебных и исполнительных документов.
Классификация и
извлечение зачастую не связаны между собой, ведь обработка кредитного досье происходит на досудебной стадии,
а
извлечение нужно на судебной и исполнительной стадиях.
Однако мы увидели, что у клиентов есть потребности, затрагивающие как оба сервиса по отдельности, так и
вместе.
Поэтому было принято решение создать продукт, внутри которого два разных сервиса смогут работать и по
отдельности, и
вместе, образуя синергию.
Ход разработки продукта
Началась разработка продукта, и мы приступили к подбору нужных алгоритмов машинного обучения и настройке
гиперпараметров. Последнее было нужно, чтобы подобрать максимально универсальные настройки под разные виды
входящих
документов досье с разным качеством.
Аналогичный процесс был при выборе, дообучении и использования алгоритмов распознавания фотографий и
изображений
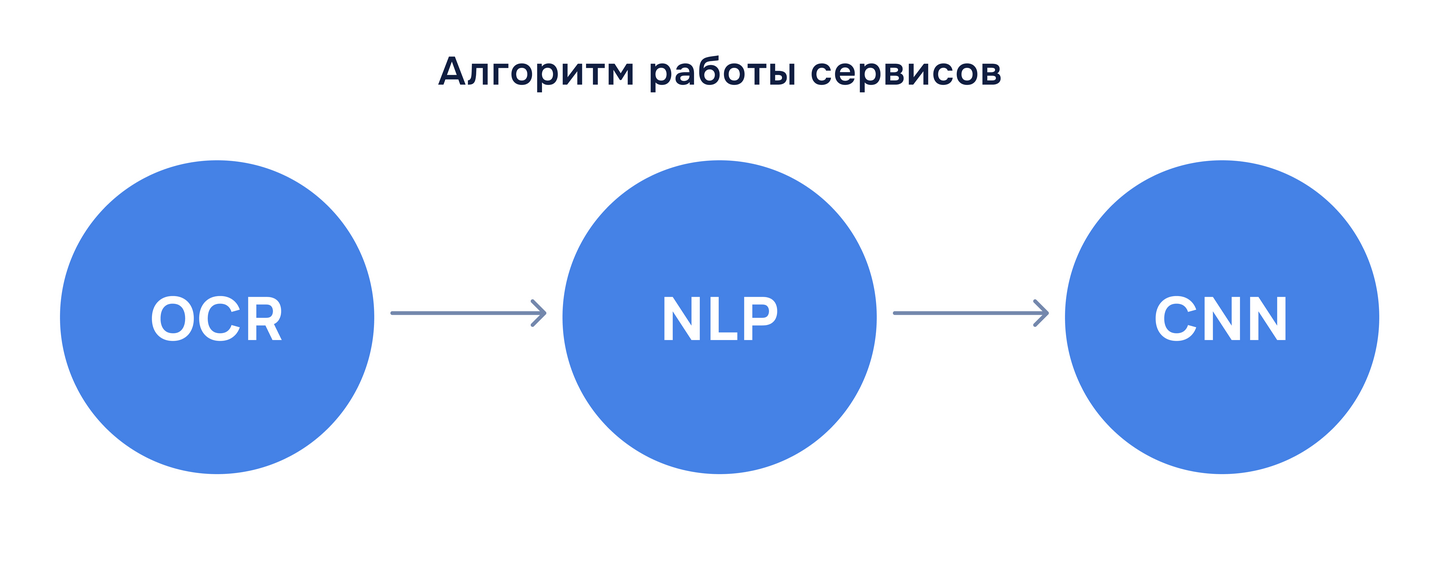
нейронных сетей. О каких именно нейронных сетях идет речь? ОКО-Скан использует в работе три стадии
распознавания
текста: машинное распознавания текста, обработка естественного языка и сверточная нейронная сеть. К примеру,
для
сверточной нейросети мы одно время искали нужные параметры свертки, ядра и размера изображения.
В конце тестов мы остановились на использовании уникального алгоритма, который с одной стороны давал качество
в
95-99% точного распознавания документов кредитного досье, а с другой стороны мог обучаться на новый тип
документов в
течении 1-2 дней.
В тестированиях нам помогала наша партнерская компания АСВ (Агентство судебного взыскания). Коллеги выступили
своего
рода песочницей, где мы проверяли гипотезы. По ходу дела вносилось много правок в продукт: как со стороны
его
функций, так и изменений самих алгоритмов классификации. Помимо «Агентства судебного взыскания», ряд близких
ему
компаний из сегментов МФО, МКК, ЖКХ предоставляли нам свои кредитные досье в разных формах, которые мы
успешно
обрабатывали нашим классификатором.
После проведения тестов и сбора обратной связи мы расширили обучающие и тестовые выборки судебных и
исполнительных
документов с 100 000 страниц до 1 млн. страниц разных судебных документов, с разным качеством этих
документов и
разным общим видом. Это дало рост качества отдельных атрибутов документов до 100%.
На протяжении всего пути мы руководствовались принципами продуктового подхода, и благодаря нему получилось
быстро
создать MVP на основании собранной обратной связи с рынка, и пытались внедрять его в процессы наших
клиентов.
Ненужный функционал постепенно отсеивался, а нужный – создавался, и после проделанной работы пришло время
выпускать
продукт в свет. На нашем пути были и трудности, их было не избежать при создании такого сложного и
масштабного
продукта.
Трудности, с которыми пришлось столкнуться
Основные трудности возникали при выборе подходящих технологий и их эффективном взаимодействии. Мы
протестировали
около 5-7 различных алгоритмов и моделей машинного обучения, а также примерно 10 видов нейросетей, прежде
чем
добились коммерчески значимых результатов. Также было сложно определить конкретные бизнес-требования, так
как у
разных клиентов было множество разнообразных документов. Кроме того, сам продукт был достаточно сложным:
некоторые
его части были монолитными, а в других использовались микросервисы.
Однако все проблемы удалось преодолеть и на выходе получился сложный, но качественно работающий продукт с
множественной каскадной архитектурой.
Итоги работы: как сейчас выглядит ОКО-Скан?
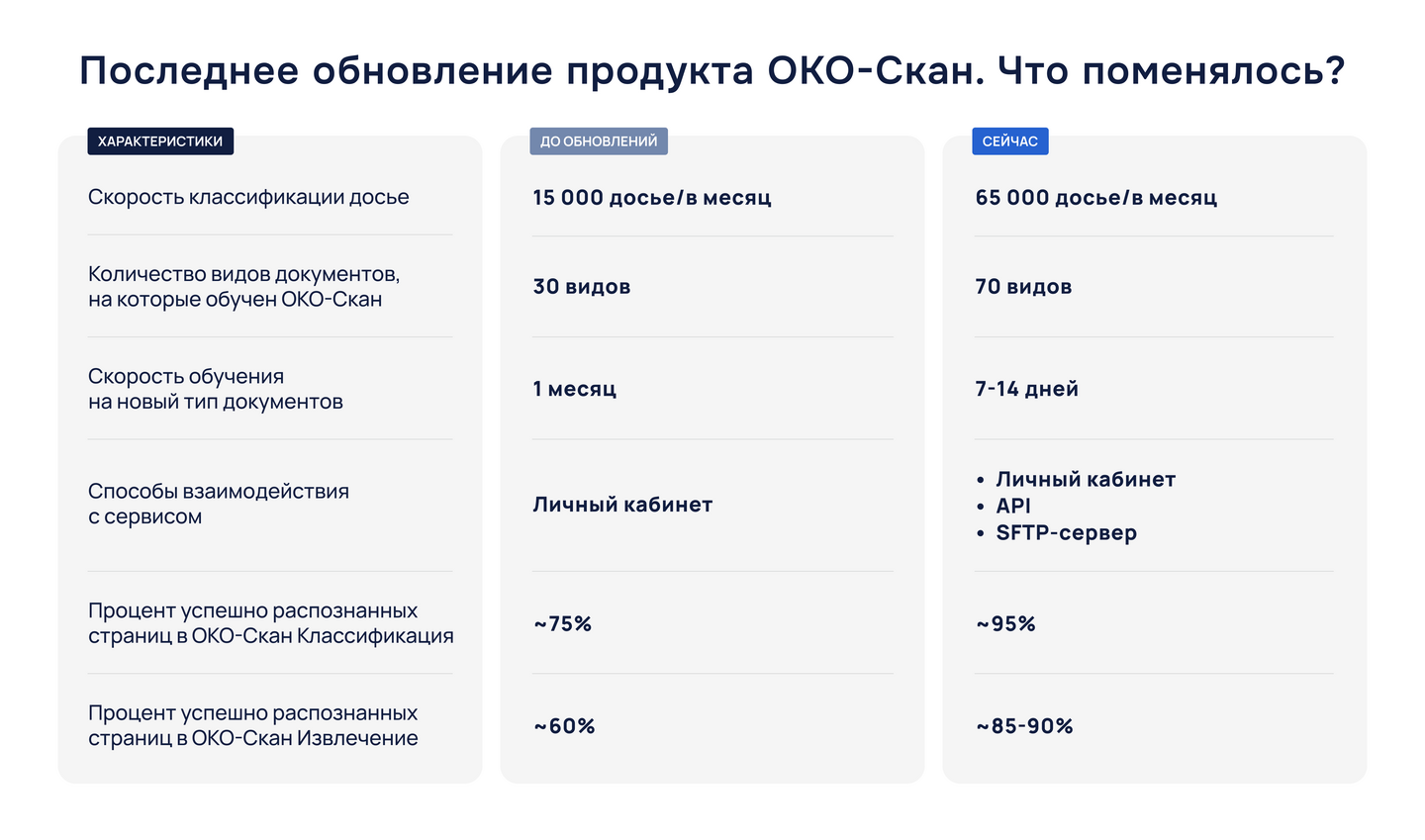
Мы продолжаем активно развивать ОКО-Скан, и последними большими обновлениями для него были улучшение
интеграции по
API, добавление обработки нескольких кредитных досье параллельно и считывания статистики по каждому заданию,
а также
теперь сервис принимает досье в виде архива, берет в классификацию и отдает результат в collection-систему.
Ранее
это было доступно только через SFTP.
Помимо этого, мы начали работу по классификации и подготовке документов для работы с электронной
исполнительной
надписью нотариуса. Процесс там такой же, как и при классификации досье для подачи в суд, но виды документов
немного
отличаются.
Также, мы продолжаем расширять пул документов, доступных для обработки и развиваем продукт в сторону гибкой
настройки
под запросы клиентов. А именно, мы уже дообучали программу под извлечение уникальных атрибутов, создавали
возможности для создания индивидуальных названий файлов и перевода ФИО из падежа в документе в именительный
падеж. И
в скором времени планируется обучить сервис «Извлечение» для распознавания рукописного текста.
ОКО-Сканом можно воспользоваться уже сейчас – в личном кабинете Youristo.online, или по API и с помощью
SFTP-сервера.
И кейсы наших клиентов показывают, что финансовые затраты на обработку документов при использовании сервиса
снижаются до 60%, а временные – до 80%.